Видео с ютуба Vla Models

LLMs Meet Robotics: What Are Vision-Language-Action Models? (VLA Series Ep.1)

Exploring Vision-Language-Action (VLA) Models: From LLMs to Embodied AI

1st Place Project: Matcha Making with GR00T VLA Model Demo - NVIDIA, HuggingFace, Seeed Hackathon

Advancing Robotics with Vision Language Action (VLA) Models | Prelim Exam Talk
![Внутри самого умного в мире роботизированного мозга [VLA]](https://imager.clipsaver.ru/2mrGMMmrVNE/max.jpg)
Внутри самого умного в мире роботизированного мозга [VLA]

OpenVLA: LeRobot Research Presentation #5 by Moo Jin Kim

VLA Models for Robotics: A Full-Stack Review

Конечная цель робототехники: Джим Фан из Nvidia
![[VLA] Vision Language models Explained: The future of AI robotics. How robots will see? [Groot]](https://imager.clipsaver.ru/YxoBVu8Tigk/max.jpg)
[VLA] Vision Language models Explained: The future of AI robotics. How robots will see? [Groot]

What Are Vision Language Models? How AI Sees & Understands Images

LingBot-VLA: VLA с увеличенной глубиной резкости! (Превосходит Pi 0.5, GR00T N1.6 и WALL-OSS)

SmolVLA: Доступная и эффективная робототехника на базе модели VLA с 450 миллионами параметров.

LingBot-VLA: Scaling VLA Models for Robotics
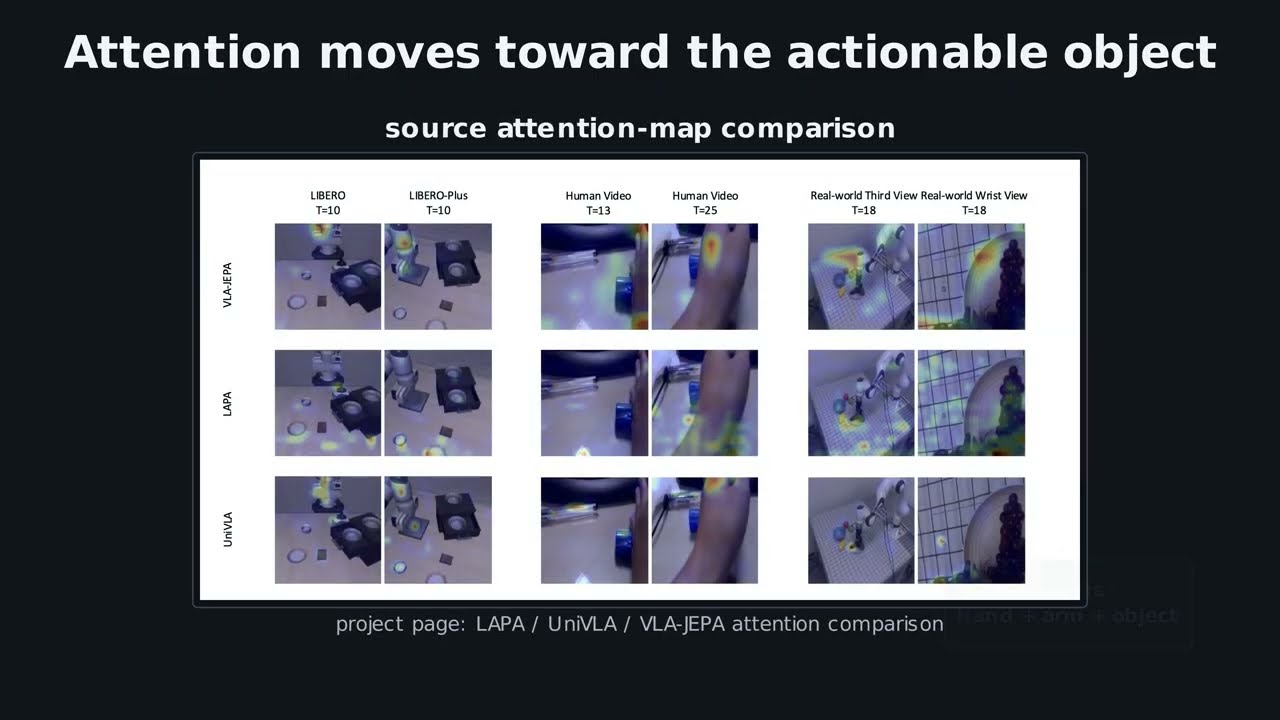
VLA-JEPA: объяснение концепции моделей латентного мира без утечек данных для обучения роботов

Agility A2 VLA Model Support | ACT Default + Optional Advanced VLA Models

Будущее робототехники: как работают модели «зрение-язык-действие» (VLA).

Vision Language Action Models - OpenVLA, π0, RT-2, Gemini Robotics
![[Reinforcement Learning] 17. Vision-Language-Action (VLA) Models](https://imager.clipsaver.ru/46WnkVu2GXg/max.jpg)
[Reinforcement Learning] 17. Vision-Language-Action (VLA) Models

Google's RT-2: The First Vision-Language-Action (VLA) Model Explained

VLA → WVLA: Unitree Just Unveiled the Next Evolution of Humanoid Robotics?